CUDA
Bibliografía
- https://www.nvidia.com/
- El DLI (Deep Learning Institute) (uma.es)
- CuPy: NumPy & SciPy for GPU
- Numba: A High Performance Python Compiler (pydata.org)
1. Introducción

Logo de Nvidia CUDA
CUDA (Compute Unified Device Architecture) es una plataforma de computación paralela y una interfaz de programación de aplicaciones (API) desarrollada por NVIDIA. Permite el uso de unidades de procesamiento gráfico (GPU) para realizar cálculos complejos con mayor eficiencia en comparación con las unidades de procesamiento central (CPU). CUDA se utiliza en áreas como la inteligencia artificial, simulaciones y renderización de gráficos.
2. Conceptos de CUDA
2.1. Introducción
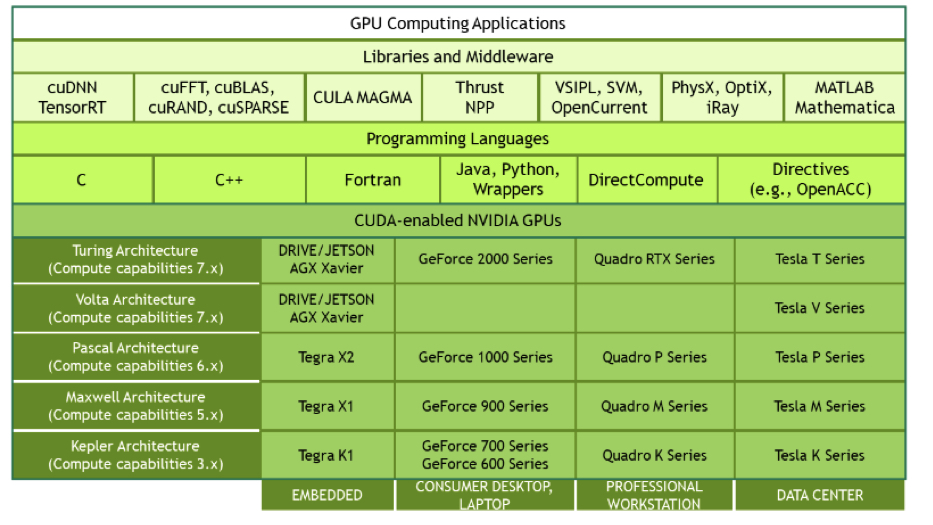
La plataforma de computación CUDA ofrece un amplio ecosistema. No obstante, en los puntos 1 y 2, se abordará el uso de CUDA en combinación con el lenguaje de programación C. A partir del punto 3, se explorarán otras bibliotecas y aplicaciones de CUDA en Python.
CUDA se basa en tres cualidades fundamentales que destacan la capacidad de la GPU para el procesamiento paralelo:
- Simplicidad: La GPU organiza los hilos en grupos de 32, conocidos como warps. Todos los hilos en un warp ejecutan la misma instrucción simultáneamente. Esta organización simplifica la gestión del paralelismo.
- Escalabilidad: La plataforma permite la creación de modelos de paralelización sostenible gracias a la abundancia de datos, especialmente en aplicaciones a gran escala. Utiliza el modelo Single Instruction Multiple Threads (SIMT) para manejar grandes volúmenes de datos de manera eficiente.
- Productividad: CUDA permite que los hilos que enfrentan latencias oculten este tiempo mediante la conmutación con otros hilos, manteniendo una alta eficiencia en el procesamiento.
2.2. Los warps en CUDA
El concepto clave en CUDA es el warp. En el nivel de hardware, un bloque de hilos se divide en warps, que son grupos de 32 hilos que ejecutan instrucciones en paralelo. Estos warps permanecen en el multiprocesador hasta completar su ejecución. Un nuevo bloque de hilos no se lanza hasta que se liberen suficientes registros y memoria compartida para los warps del nuevo bloque. La conmutación inmediata entre los hilos dentro de un warp contribuye a una ejecución eficiente.
CUDA combina software, firmware y hardware para ofrecer una plataforma de computación paralela robusta:
- Software: Proporciona extensiones SIMD que permiten la programación eficiente de la GPU, facilitando la ejecución paralela y escalable.
- Firmware: Incluye drivers para la programación GPU, que soportan tareas como renderizado, manejo de APIs y gestión de memoria.
- Hardware: Habilita el paralelismo general de la GPU, optimizando la capacidad de procesamiento paralelo.
2.3. Computación heterogénea
Aunque CUDA ofrece ventajas significativas, es crucial equilibrar la carga de trabajo entre la GPU y la CPU, un enfoque conocido como computación heterogénea, la cual se basa en:
- GPU: Orientada al procesamiento intensivo en datos y paralelismo fino.
- CPU: Adecuada para operaciones con saltos y bifurcaciones, y paralelismo grueso.
Es fundamental identificar qué partes del código se benefician de la paralelización en la GPU y cuáles deben procesarse secuencialmente en la CPU.
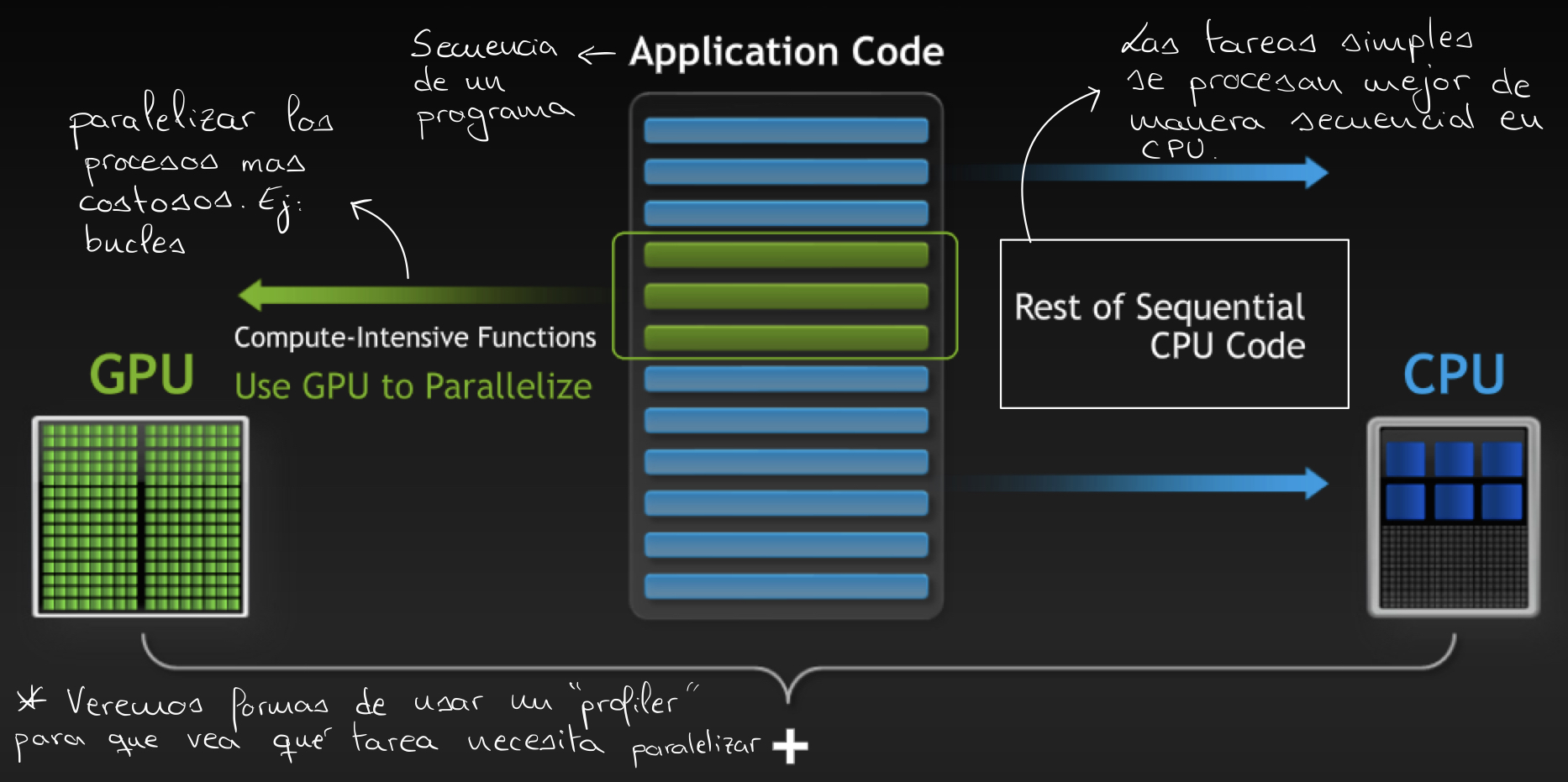
Vemos por tanto que el paralelismo por el que CUDA destaca es en el paralelismo de datos (data parallelism).
2.4. Hardware
Una GPU está compuesta por N multiprocesadores, cada uno de los cuales contiene M núcleos. Algunas de las familias de GPU de la familia Tesla de NVidia se muestran en la siguiente imagen.
-ee4f91628ee366cb96f6df6ccd212845.png)
Cada multiprocesador dispone de su propio banco de registros, memoria compartida, una caché de constantes y una caché de texturas (ambas de sólo lectura). Además, está equipada con una memoria global de tipo GDDR, que es tres veces más rápida que la memoria principal de la CPU, aunque mucho más lenta que la memoria compartida de tipo SRAM. Los bloques de hilos en CUDA pueden ser asignados a cualquier multiprocesador para su ejecución. La imagen siguiente ilustra la estructura de una GPU.
-120824bf9a525cfdefe4291c0f1d5405.png)
Para ilustrar, consideremos la generación Volta, específicamente la GPU GV100. Esta GPU cuenta con 84 multiprocesadores (SMs) y 8 controladores de memoria de 512 bits. En la arquitectura Volta, cada multiprocesador tiene 64 núcleos para operaciones de tipo int32, 64 núcleos para float32, 32 núcleos para float64 y 8 unidades tensoriales.
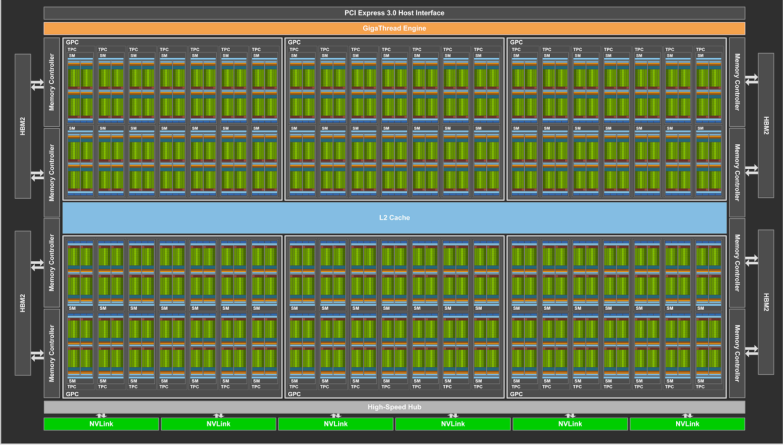
De la imagen anterior se observa que el diseño de un bloque se utiliza como base para crear diseños más complejos al replicarlo.
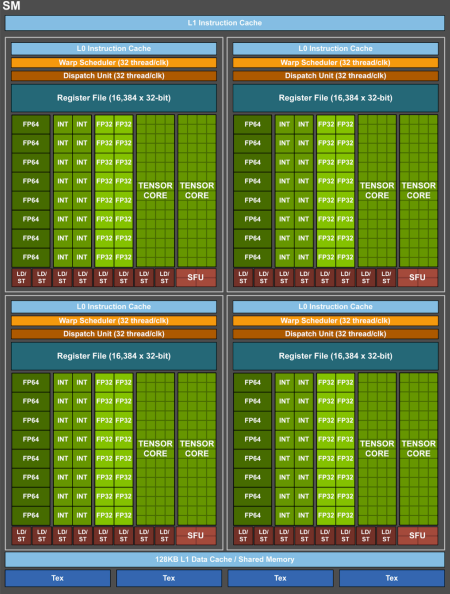
2.4.1. Núcleos tensoriales
En la última década, uno de los componentes que mayor protagonismo ha tomado han sido los núcleos tensoriales. Los núcleos tensoriales están diseñados para realizar operaciones matriciales a alta velocidad, lo que resulta crucial en el entrenamiento de modelos de Inteligencia Artificial y en procesos que implican operaciones matriciales extensivas. El siguiente diagrama ilustra el proceso de operación de cada núcleo tensorial por ciclo de reloj.
-619199202455b06c0d7be3094f6bc819.png)
2.4.2. Precisión numérica
La precisión de los datos, como pasar de enteros de 32 bits a enteros de 16 bits, impacta en la tasa de transferencia (Throughput) del sistema. Reducir la precisión permite realizar un mayor número de operaciones, aunque con una precisión menor en los resultados. Dependiendo de la aplicación, esta reducción de precisión puede ser aceptable. A continuación, se muestra el Throughput para diferentes precisiones de datos en arquitecturas de GPU modernas.
-72848be053bd81c42f20515ac1889fd7.png)
3. Programación con CUDA en C
3.1. Conceptos básicos
En CUDA, una función paralelizada se denomina Kernel. Para conocer la GPU y sus características se puede utilizar el siguiente comando en una terminal del equipo a utilizar:
nvidia-smi
Durante la programación en CUDA, tanto la CPU como la GPU realizan operaciones simultáneamente, por lo que es necesario sincronizar los tiempos de ejecución entre ambos componentes.
-404030453f720e6b89dd06fec3aeff94.png)
La sincronización entre la GPU y la CPU, así como entre diferentes hilos en la GPU, puede
hacer que las sentencias condicionales como if sean desfavorables para la ejecución en
la GPU. Por tanto, se recomienda minimizar el uso de sentencias condicionales en un
Kernel.
La programación en CUDA se realiza utilizando C/C++ y los archivos CUDA tienen la
extensión .cu. La compilación del código se lleva a cabo con el siguiente comando:
!nvcc -arch=sm_70 -o resultado_nombre programa.cu -run
En este comando, -arch=sm_70 especifica la arquitectura para la compilación.
A continuación se presenta un ejemplo de código en CUDA:
// Incluye la biblioteca estándar para entrada y salida
#include <iostream>
// Permite usar el espacio de nombres estándar sin prefixar std::
using namespace std;
void hola_cpu(void)
{
// Imprime un mensaje en la consola desde la CPU
printf("Esto es un saludo desde la CPU");
}
// Define una función de kernel que se ejecuta en la GPU
__global__ void ejemplo_kernel(void)
{
// Imprime un mensaje en la consola desde la GPU
printf("Hola, esto se está ejecutando de forma paralela en GPU");
}
int main(void)
{
// Llama a la función hola_cpu para imprimir el saludo desde la CPU
hola_cpu();
// Llama a la función de kernel en la GPU con una sola instancia de un solo hilo
ejemplo_kernel<<<1, 1>>>();
// Espera a que todos los hilos en la GPU terminen antes de continuar
cudaDeviceSynchronize();
// Retorna 0 para indicar que el programa terminó correctamente
return 0;
}
La palabra clave __global__ indica que la función se ejecuta en la GPU y puede ser
invocada desde la CPU. El código ejecutado en la CPU se denomina host y el código
ejecutado en la GPU se denomina device. Las funciones __global__ deben tener el
tipo void(). La invocación de una función CUDA utiliza la configuración de
ejecución, que tiene la siguiente forma: nombre_funcion<<<x, y>>>, donde:
xes el número de bloques, debe ser menor a 2048.yes el número de hilos por bloque, debe ser menor a 1024.
El número total de hilos se obtiene multiplicando x por y. Por ejemplo, con 2 bloques
(x = 2) y 4 hilos por bloque (y = 4), se obtienen 8 hilos en total. El número de
bloques y hilos depende de las capacidades de hardware de la GPU.
El código del kernel se ejecuta en cada hilo de cada bloque configurado cuando se lanza el kernel. Un kernel con un solo bloque utilizará solo un multiprocesador de la GPU.
El comando cudaDeviceSynchronize() asegura que la GPU complete su tarea antes de que la
CPU finalice el programa, funcionando como una herramienta de sincronización entre CPU y
GPU.
CUDA puede agilizar los bucles en la programación. Por ejemplo, para incrementar un valor
b a los N elementos de un vector:
void incremento_en_cpu(float *a, float b, int N)
{
// Recorre cada elemento del arreglo desde 0 hasta N-1
for (int idx = 0; idx < N; idx++)
{
// Incrementa el valor en la posición 'idx' del arreglo 'a' por 'b'
a[idx] = a[idx] + b;
}
}
void main()
{
// ... (otras posibles inicializaciones y configuraciones)
// Llama a la función incremento_en_cpu para incrementar los elementos del arreglo 'a' en la CPU
incremento_en_cpu(a, b, N);
}
El bucle anterior es adecuado para la paralelización, ya que cada índice es independiente y no requiere un orden específico (las hebras en un warp se ejecutan desordenadamente).
3.1.1. Identificar hilos, bloques y mallas en un kernel de CUDA
CUDA proporciona variables que describen los hilos, bloques y mallas (grid):
| Función | Definición |
|---|---|
gridDim.x | Número total de bloques en la malla. |
blockIdx.x | Índice del bloque actual dentro de la malla. |
blockDim.x | Número de hilos en un bloque dentro del kernel. |
threadIdx.x | Índice de un hilo dentro de un bloque en el kernel. |
Los bloques de un mismo kernel no pueden comunicarse entre sí durante su ejecución, ya que pueden ejecutarse en cualquier orden y de forma independiente.
El kernel debe realizar el trabajo de una sola iteración del bucle, por lo que la configuración del kernel debe ajustarse al número de iteraciones del bucle, configurando adecuadamente tanto el número de bloques como el número de hilos por bloque. A continuación, se presenta el código paralelizado del bucle:
// Función de kernel para incrementar cada elemento del arreglo 'a' en la GPU
__global__ void incremento_en_gpu(float *a, float b, int N)
{
// Calcula el índice global del hilo
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// Verifica si el índice está dentro del rango válido
if (idx < N)
{
// Incrementa el valor en la posición 'idx' del arreglo 'a' por 'b'
a[idx] = a[idx] + b;
}
}
void main()
{
// ... (otras posibles inicializaciones y configuraciones)
// Define el tamaño de cada bloque de hilos
dim3 dimBlock(blocksize);
// Calcula el número de bloques necesarios para cubrir todos los elementos del arreglo
dim3 dimGrid(ceil(N / (float)blocksize));
// Llama a la función de kernel en la GPU con la configuración de bloques y hilos
incremento_en_gpu<<<dimGrid, dimBlock>>>(a, b, N);
}
En el código anterior, cada hilo realiza una iteración del bucle. La fórmula para mapear cada hilo a un índice del bucle es:
-d782c69fe2106758fa005487cf079f5b.png)
Es importante que blockDim.x sea mayor o igual a 32, que es el tamaño del warp.
En casos donde el número de hilos excede el número de tareas, se debe asegurar que el índice obtenido sea menor que el número total de datos.
-122291ca1d39ad2fd0798dd1e3a71496.png)
3.2. Asignación de memoria en GPU
La asignación y liberación de memoria se realiza para la CPU y la GPU utilizando las
funciones malloc() y free() en la CPU, y cudaMallocManaged() y cudaFree() en la
GPU.
Ejemplo para la CPU:
// Sólo para CPU
// Define el tamaño del arreglo como 2^21
int N = 2 << 20;
// Calcula el tamaño total en bytes del arreglo
size_t size = N * sizeof(int);
// Declara un puntero para el arreglo
int *a;
// Asigna memoria para el arreglo en el heap de la CPU
a = (int *)malloc(size);
// Libera la memoria asignada en el heap de la CPU
free(a);
// Acelerado con GPU y CUDA
// Define el tamaño del arreglo como 2^21
int N = 2 << 20;
// Calcula el tamaño total en bytes del arreglo
size_t size = N * sizeof(int);
// Declara un puntero para el arreglo
int *a;
// Asigna memoria unificada para el arreglo en la GPU y la CPU
cudaMallocManaged(&a, size);
// Libera la memoria unificada
cudaFree(a);
Gracias a los avances en hardware, se ha logrado mejorar la tasa de transferencia entre la CPU y la GPU, así como las características de la memoria en ambos componentes. Las versiones recientes de CUDA permiten el uso de memoria unificada, que facilita el intercambio de datos entre la CPU y la GPU.
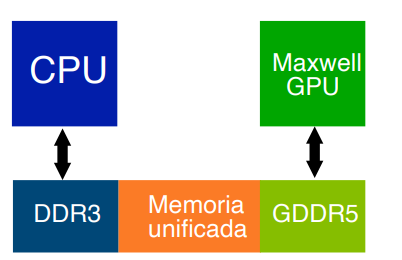
La memoria unificada ofrece una serie de ventajas:
- Proporciona un único puntero a los datos accesible tanto desde la CPU como desde la GPU.
- Elimina la necesidad de usar
cudaMemcpy(). - Facilita la portabilidad del código.
- Mejora el rendimiento en la transferencia de datos y asegura la coherencia global de
los datos. También permite la optimización manual con
cudaMemcpyAsync().
Los tipos de memoria en CUDA se pueden observar en la imagen siguiente:
-34f85fe1300dbf292f7a4a71e65b1f85.png)
La memoria unificada presenta algunas consideraciones:
- La capacidad máxima de memoria unificada está limitada por la menor cantidad de memoria disponible en las GPUs.
- La memoria unificada utilizada por la CPU debe migrar de nuevo a la GPU antes de lanzar un kernel.
- La CPU no puede acceder a la memoria unificada mientras la GPU está ejecutando un
kernel; se debe llamar a
cudaDeviceSynchronize()antes de que la CPU acceda a la memoria unificada. - La GPU tiene acceso exclusivo a la memoria unificada mientras ejecuta un kernel, incluso si el kernel no utiliza la memoria unificada.
Podemos resumir el proceso de la memoria unificada con la siguiente imagen:

Ejemplos de uso de memoria unificada
Ejemplo incorrecto:
// Define una variable global de memoria unificada accesible desde la CPU y la GPU
__device__ __managed__ int x, y = 2;
__global__ void mykernel()
{
// Asigna el valor 10 a la variable 'x' en la GPU
x = 10;
}
int main()
{
// Llama a la función de kernel en la GPU con una sola instancia de un solo hilo
mykernel <<<1, 1>>> ();
// ERROR: Acceso concurrente desde la CPU mientras la GPU puede estar usando la variable 'y'
y = 20;
return 0;
}
Ejemplo correcto:
// Define una variable global de memoria unificada accesible desde la CPU y la GPU
__device__ __managed__ int x, y = 2;
__global__ void mykernel()
{
// Asigna el valor 10 a la variable 'x' en la GPU
x = 10;
}
int main()
{
// Llama a la función de kernel en la GPU con una sola instancia de un solo hilo
mykernel <<<1, 1>>> ();
// Espera a que todos los hilos en la GPU terminen antes de continuar
cudaDeviceSynchronize();
// Asigna el valor 20 a la variable 'y' en la CPU, después de que el kernel haya terminado
y = 20;
return 0;
}
Es posible clonar estructuras sin usar memoria unificada, pero esto requiere realizar copias sucesivas entre la CPU y la GPU. También es posible hacerlo con memoria unificada utilizando C++.
3.4. Kernels con gran tamaño de datos
Cuando se trabaja con una cantidad de datos que excede el número máximo de hebras disponibles, es necesario dividir los datos en bloques más pequeños que se ajusten al número de hebras. Tras completar el procesamiento de una división, se pasa a la siguiente utilizando la expresión:
El siguiente bucle ilustra cómo implementar esta técnica:
__global__ void kernel(int *a, int N)
{
// Calcula el índice global del hilo dentro de la cuadrícula
int indexWithinTheGrid = (blockIdx.x * blockDim.x) + threadIdx.x;
// Calcula el tamaño total de la cuadrícula en t�érminos de hebras
int gridStride = blockDim.x * gridDim.x;
// Recorre los datos en pasos de tamaño 'gridStride' para asegurar que todas las hebras procesen partes del arreglo
for (int i = indexWithinTheGrid; i < N; i += gridStride)
{
// Código para procesar los datos
}
}
3.5. Manejo de errores
Las funciones de CUDA a menudo devuelven un valor que indica si se ha producido un error, facilitando el manejo de errores. A continuación, se muestra cómo gestionar errores al reservar memoria:
// Declara una variable para almacenar el código de error de CUDA
cudaError_t err;
// Asigna memoria unificada para el arreglo 'a' en la GPU y la CPU
err = cudaMallocManaged(&a, N);
// Verificar el resultado de la asignación de memoria
if (err != cudaSuccess)
{
// Imprime un mensaje de error si la asignación falló
printf("Error: %s\n", cudaGetErrorString(err));
}
Para la gestión de errores al lanzar un kernel, se utiliza cudaGetLastError(), que
devuelve un valor de tipo cudaError_t. Por ejemplo:
// -1 no es un valor válido para el número de hebras por bloque
someKernel<<<1, -1>>>();
// Declara una variable para almacenar el código de error de CUDA
cudaError_t err;
// Obtiene el último error ocurrido en la API de CUDA
err = cudaGetLastError();
// Verificar el resultado del último error
if (err != cudaSuccess)
{
// Imprime un mensaje de error si ocurrió un problema
printf("Error: %s\n", cudaGetErrorString(err));
}
También se puede emplear una función auxiliar para verificar errores:
#include <stdio.h>
#include <assert.h>
// Función inline para verificar errores de CUDA y reportarlos si ocurren
inline cudaError_t checkCuda(cudaError_t result)
{
// Si el resultado no es cudaSuccess, imprime el mensaje de error y usa assert para detener el programa
if (result != cudaSuccess)
{
fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
return result;
}
int main()
{
// Llama a checkCuda para gestionar los errores de las funciones CUDA
checkCuda(todas_las_funciones_a_gestionar_errores);
}
3.6. Ejemplos de Kernels característicos/comunes
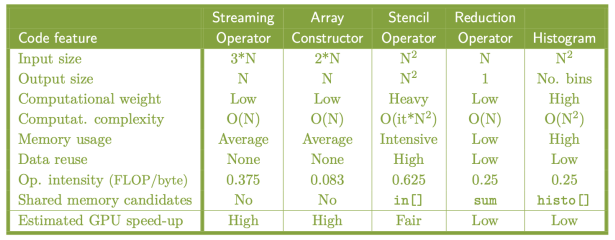
Antes de explorar los operadores, se debe definir un bucle forall:
Un bucle forall es un bucle
forsin dependencias entre iteraciones, lo que permite que el resultado no se vea alterado independientemente del índice de inicio.
Los tipos de operadores más comunes son:
-
Operadores streaming: Representan la forma más simple de un bucle forall. CUDA puede utilizar todos los hilos necesarios para procesar cada píxel de manera independiente. Ejemplo:
// Define el tamaño del arreglo basado en una resolución de 1920x1080
#define N 1920 * 1080
// Declara arreglos para los componentes de color y la luminancia
float r[N], g[N], b[N], luminancia[N];
// Calcula la luminancia para cada píxel
for(int i = 0; i < N; i++)
{
// Calcula la luminancia usando la fórmula de luminancia relativa
luminancia[i] = 255 * (0.2999 * r[i] + 0.587 * g[i] + 0.114 * b[i]);
} -
Operadores sobre vectores: Cada iteración del bucle puede ser asignada a un hilo CUDA para maximizar el paralelismo y la escalabilidad. Ejemplo:
// Define el tamaño del arreglo como 2^30
#define N (1 << 30)
// Declara arreglos para los vectores a, b y c
float a[N], b[N], c[N];
// Suma los elementos correspondientes de los arreglos 'a' y 'b' y almacena el resultado en 'c'
for(int i = 0; i < N; i++)
{
c[i] = a[i] + b[i];
} -
Operadores patrón (stencil operators): Las iteraciones externas deben serializarse debido a dependencias, pero se puede aprovechar el paralelismo en cada partícula. La carga computacional depende del número de iteraciones. Ejemplo:
int i, j, iter, N, Niters;
// Declara dos arreglos bidimensionales para almacenar datos de entrada y salida
float in[N][N], out[N][N];
// Realiza la iteración sobre un número fijo de iteraciones
for (iter = 0; iter < Niters; iter++)
{
// Calcula el promedio de los vecinos para cada elemento en la matriz, excluyendo los bordes
for (i = 1; i < N - 1; i++)
{
for (j = 1; j < N - 1; j++)
{
out[i][j] = 0.2 * (in[i][j] + in[i-1][j] + in[i+1][j] + in[i][j-1] + in[i][j+1]);
}
}
// Copia los resultados calculados en 'out' de vuelta a 'in' para la siguiente iteración
for (i = 1; i < N - 1; i++)
{
for (j = 1; j < N - 1; j++)
{
in[i][j] = out[i][j];
}
}
}El paralelismo en este caso está determinado por el tamaño de la matriz 2D ().
-
Operadores de reducción: Aunque el código tiene dependencias entre iteraciones, el paralelismo puede ser desplegado mediante una estructura en árbol binario, resultando en pasos que reducen el grado de paralelismo hasta llegar a un solo hilo. Es fundamental usar un patrón de acceso a memoria que optimice la jerarquía de memoria de la GPU. Ejemplo:
// Declara una variable para almacenar la suma y un arreglo de números
float sum, x[N];
// Inicializa la variable de suma en 0
sum = 0;
// Suma todos los elementos del arreglo 'x'
for (int i = 0; i < N; i++)
{
sum += x[i];
} -
Histogramas: Ejemplo de código para calcular histogramas:
// Declara un arreglo para el histograma y una matriz para la imagen
int histo[Nbins], image[N][N];
// Inicializa el histograma a 0 para todos los bin
for (int i = 0; i < Nbins; i++)
{
histo[i] = 0;
}
// Calcula el histograma de la imagen
for (int i = 0; i < N; i++)
{
for (int j = 0; j < N; j++)
{
// Incrementa el contador en el bin correspondiente al valor de la imagen
histo[image[i][j]]++;
}
}El primer bucle
fortiene baja carga computacional. Los siguientes bucles tienen dependencias, pero se pueden leer en paralelo si se asignan a hilos CUDA. CUDA proporciona operaciones atómicas (atomicInc(histo[image[i][j]])) para manejar accesos concurrentes al vectorhisto[]y prevenir condiciones de carrera.
Como análisis final tenemos:
- El operador streaming es el más eficiente en GPU.
- El operador patrón aprovecha mejor la memoria compartida.
- El operador de reducción requiere una mayor intervención del programador.
- El histograma es el más desafiante para el programador.
4. Acelerar aplicaciones con CUDA en Python utilizando Numba y CuPy
El rendimiento de las aplicaciones científicas y de ingeniería en Python se puede mejorar significativamente mediante el uso de herramientas como Numba y CuPy. Estas tecnologías permiten la paralelización y aceleración del código, aprovechando la potencia de procesamiento de las GPUs y superando las limitaciones del intérprete de Python.
4.1. Numba
4.1.1. Introducción
Numba es un compilador JIT (Just-In-Time) para Python que acelera el código al convertir funciones en código máquina optimizado para CPU y GPU. Esto evita el intérprete de Python y permite la ejecución eficiente de operaciones numéricas, especialmente aquellas que involucran bucles y cálculos intensivos. La compilación se realiza en tiempo de ejecución, aplicando optimizaciones basadas en los datos de entrada.
Sin embargo, Numba presenta ciertas limitaciones como el no ser compatible con Pandas, por lo que para utilizar Numba con datos de Pandas, se recomienda convertir los DataFrames a matrices de NumPy o CuPy. Para más información, consultar la página oficial de Numba.
4.1.2. Decoradores
Numba ofrece varios decoradores para la compilación y optimización de funciones:
| Decorador | Definición |
|---|---|
@jit | Compila en modo objeto. Numba compila los bucles optimizables a código máquina y el resto de la función se ejecuta con el intérprete de Python. |
@njit = @jit(nopython=True) | Compila sin el intérprete de Python, obteniendo el mejor rendimiento. Puede fallar si los parámetros no son compatibles; si falla, se recomienda utilizar @jit. Este es el decorador preferido para la mayoría de los casos. |
@njit(parallel=True) | Compila el código para ejecutarse en múltiples hilos, aprovechando la paralelización cuando las operaciones lo permiten. |
@njit(fastmath=True) | Habilita cálculos matemáticos rápidos a costa de reducir la precisión numérica, acelerando aún más el rendimiento. |
Los decoradores pueden combinarse para optimizar el rendimiento. Por ejemplo:
@njit(parallel=True, fastmath=True)
En este caso, se evita el intérprete de Python (njit), se paraleliza el código
(parallel=True) y se permite una menor precisión numérica (fastmath=True) para
maximizar la velocidad de ejecución.
Ejemplo
Ejemplo básico de uso de Numba con el decorador @njit:
from numba import njit
import numpy as np
@njit()
def bucle(lista1, lista2, num_filas):
## Inicializa una lista vacía para almacenar los resultados
lista3 = []
## Recorre cada fila
for fila in range(num_filas):
## Verifica si el valor en lista1 es mayor o igual a 1 y el valor en lista2 es menor o igual a 5
if (lista1[fila] >= 1) and (lista2[fila] <= 5):
## Calcula la media de los valores en lista1 y lista2 para esa fila y lo agrega a lista3
lista3.append(np.mean([lista1[fila], lista2[fila]]))
return lista3
lista1 = np.array([1, 2, 3])
lista2 = np.array([4, 5, 6])
result = bucle(lista1, lista2, len(lista1))
print(result)
En este ejemplo, el decorador @njit() compila la función para ejecutarse sin el
intérprete de Python, mejorando notablemente el rendimiento.
4.2. CuPy
4.2.1. Introducción
CuPy es una biblioteca de Python diseñada para acelerar cálculos numéricos mediante la ejecución de código en GPUs. Ofrece una API similar a NumPy, permitiendo realizar operaciones similares aprovechando la arquitectura de CUDA para mejorar el rendimiento. Es útil en tareas que involucran grandes volúmenes de datos o cálculos intensivos.
Para más información, consultar la página oficial de CuPy.
4.2.2. Uso básico de CuPy
CuPy ofrece una API similar a NumPy, facilitando la transición entre ambas bibliotecas. A continuación se presenta un ejemplo básico de cómo realizar cálculos en una GPU utilizando CuPy:
import cupy as cp
## Crear matrices en la GPU
a = cp.array([1, 2, 3, 4, 5])
b = cp.array([6, 7, 8, 9, 10])
## Realizar operaciones
c = a + b
## Convertir de vuelta a NumPy si es necesario
c_numpy = cp.asnumpy(c)
print(c_numpy) ## Resultado: [ 7 9 11 13 15]
4.3. Comparación entre Numba y CuPy
- Numba: Ideal para acelerar funciones específicas y bucles en Python. Permite compilación JIT para CPU y GPU, y se integra bien con código existente de NumPy. Recomendado para optimizar algoritmos matemáticos complejos y simulaciones con estructuras de bucles que pueden beneficiarse de la compilación JIT.
- CuPy: Mejor para trabajar con matrices y realizar operaciones a gran escala en GPUs. Ofrece una API similar a NumPy, facilitando la migración de código y aprovechando el hardware de CUDA. Adecuado para tareas que involucren cálculos matriciales intensivos, como el entrenamiento de modelos de machine learning, procesamiento de imágenes y simulaciones con alta densidad de datos.