MLOps
Actualmente, no es la mejor opción para tu aprendizaje, ya que no está terminado. Estoy utilizando este espacio para probar que todo funciona correctamente y para planificar cómo estructurar el contenido final.
Te agradezco mucho tu paciencia y comprensión. Soy solo una persona trabajando en esto, y a veces no me da tiempo para todo. ¡Espero pronto tener algo genial para ti!
Bibliografía
1. Introducción
![]()
Ciclo de vide de un proyecto MLOps
MLOps, o Machine Learning Operations, es el conjunto de prácticas, herramientas y procesos que permiten desarrollar, implementar y mantener modelos de machine learning en entornos de producción. Este enfoque combina conocimientos de ingeniería de software, computación en la nube y gestión de redes, siendo fundamental para garantizar que los modelos sean eficaces, escalables y sostenibles.
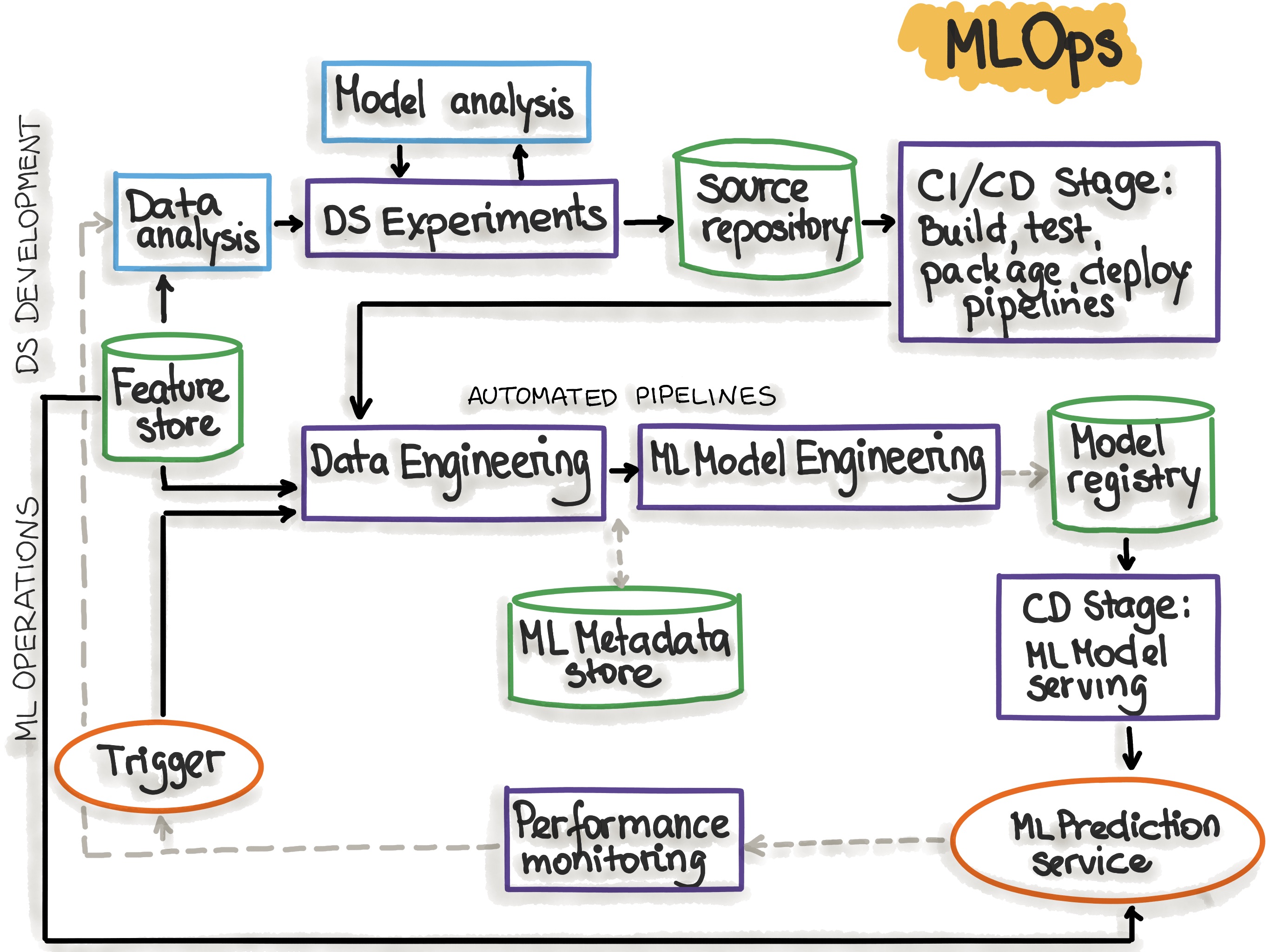
Ejemplo de los pasos seguidos en un proyecto de MLOps
Un sistema de MLOps se compone de diversos elementos. En su núcleo está el modelo o algoritmo, que representa la solución entrenada en datos. Este modelo opera sobre una infraestructura que puede variar desde servicios en la nube hasta servidores locales o en los propios dispositivos (on edge), dependiendo de las necesidades. Una API o interfaz es esencial para procesar solicitudes y devolver predicciones, mientras que la gestión de predicciones y la monitorización aseguran la calidad, fiabilidad y rendimiento en tiempo real.
2. Los desafíos de MLOps
Uno de los principales desafíos en la adopción de metodologías de MLOps es la correcta definición tanto del problema como de la posible solución. Además, es fundamental implementar tecnologías que puedan comunicarse eficazmente entre sí, permitiendo la creación de sistemas y procesos automatizados que agilicen la recopilación, el tratamiento, el análisis y el uso de los datos. Este enfoque requiere una infraestructura sólida, cuyo diseño y construcción demandan tiempo y conocimientos especializados.
Una vez establecida la infraestructura necesaria para integrar los diferentes componentes, surgen nuevos retos en la etapa de puesta en producción.
Entre ellos destaca el data drift, que ocurre cuando los datos de producción difieren de los de entrenamiento, afectando la precisión del modelo. Otro desafío común es el manejo de datos fuera de distribución (Out of Distribution, OOD), aquellos que no encajan con los patrones aprendidos durante el entrenamiento. Además, la actualización y el mantenimiento de los modelos para adaptarlos a nuevos datos o requerimientos constituyen un esfuerzo continuo.
El mantenimiento de modelos basados en inteligencia artificial suele implicar su reentrenamiento con nuevos datos para evitar la degradación de las métricas establecidas y asegurar un rendimiento óptimo.
2.1. Ciclo de vida de MLOps
El ciclo de vida de MLOps es un proceso iterativo que permite realizar ajustes en cualquier etapa para optimizar el sistema. Un diseño efectivo de un producto basado en machine learning debe justificar su necesidad, detallar sus objetivos e impacto, y abordar las siguientes áreas clave:
-
Definición del proyecto: En esta etapa se identifican las necesidades del usuario y los objetivos del producto, además de evaluar la viabilidad técnica y financiera. Los pasos esenciales incluyen:
- Identificación de problemas y métricas clave: Métricas como precisión, latencia y ROI (Retorno de Inversión) son fundamentales para medir el éxito del proyecto.
- Propuesta de valor: Se define cómo el producto resolverá problemas específicos y generará beneficios para los usuarios.
- Factibilidad: Se evalúan los recursos necesarios (humanos, tecnológicos y financieros) para implementar la solución.
- Planificación: Se establecen cronogramas y se asignan recursos para el desarrollo del producto.
-
Datos: El manejo de datos es la base de cualquier sistema de ML. Incluye los siguientes procesos:
- Recopilación y organización: Los datos pueden provenir de bases de datos, archivos o servicios web. En proyectos complejos, el almacenamiento en la nube es una opción ideal.
- Etiquetado y preprocesamiento: Incluye normalización, codificación y extracción de características para garantizar que los datos sean adecuados para el entrenamiento.
- Análisis exploratorio de datos (EDA): Se analiza la distribución de los datos, se identifican anomalías y se descubren correlaciones relevantes.
- Manejo de desequilibrios: Técnicas como el sobremuestreo o submuestreo equilibran clases desbalanceadas, asegurando que los datos sean representativos.
- División en conjuntos: Los datos se dividen en conjuntos de entrenamiento, validación y prueba, manteniendo distribuciones similares para evitar problemas como el sobreajuste.
-
Modelado: El modelado implica seleccionar, entrenar y validar modelos de ML. Las principales actividades incluyen:
- Desarrollo iterativo: Se comienza con soluciones base y se incrementa la complejidad según sea necesario.
- Optimización: Herramientas como Ray permiten el entrenamiento distribuido en sistemas escalables, mientras que técnicas como pruning, quantization y distillation optimizan modelos grandes.
- Ajuste de hiperparámetros y seguimiento de experimentos: Se experimenta con configuraciones para obtener un rendimiento óptimo, guiándose por métricas específicas como F1 en clasificaciones desbalanceadas.
- Despliegue del modelo: Los modelos se implementan como servicios robustos, ya sea para predicciones en tiempo real o por lotes, asegurando personalización, pruebas exhaustivas y escalabilidad.
-
Despliegue: El modelo se implementa inicialmente en entornos de preproducción, donde se evalúa con un número limitado de usuarios o bajo condiciones controladas. Posteriormente, se despliega en producción, aumentando gradualmente el tráfico de usuarios mientras se monitorizan métricas clave y se configuran alertas para detectar anomalías.
-
Mantenimiento: Incluye el entrenamiento continuo con datos recientes y la monitorización constante para identificar y resolver problemas de rendimiento, asegurando que el modelo siga cumpliendo los objetivos establecidos.
Un diseño robusto debe abarcar todos los elementos necesarios, desde la ingesta de datos hasta la entrega de predicciones, tomando en cuenta:
- Carga de trabajo ML: Definición de fuentes de datos, etiquetado y selección de características.
- Inferencia: Elección entre inferencia en lotes o en tiempo real, dependiendo de los requisitos del sistema.
- Impacto real: Garantizar que el sistema genere valor tangible y que su rendimiento mejore continuamente.
Este enfoque integral e iterativo asegura que los sistemas de ML sean sostenibles, escalables y efectivos en el mundo real.
2.2. Estrategias de despliegue
Existen diversas técnicas para implementar modelos en producción de manera segura y con el mínimo impacto:
- Gradual ramp-up: Consiste en incrementar progresivamente el tráfico hacia el nuevo modelo, lo que permite monitorear su desempeño y hacer ajustes según sea necesario.
- Rollback: Esta estrategia permite revertir rápidamente al modelo anterior en caso de que el nuevo no cumpla con las expectativas o falle.
- Canary deployment: En esta técnica, se asigna inicialmente un pequeño porcentaje de tráfico al nuevo modelo, incrementándolo gradualmente si demuestra ser eficaz y estable.
- Blue-green deployment: Utiliza dos entornos paralelos (uno activo y otro de prueba), lo que facilita la implementación de cambios y una rápida recuperación en caso de problemas.
2.3. Consideraciones de desarrollo
El desarrollo de modelos de ML puede seguir dos enfoques principales: model-centric, enfocado en optimizar algoritmos, y data-centric, que prioriza la mejora de la calidad de los datos, lo cual es esencial para garantizar un buen rendimiento en producción.
Es crucial realizar un sanity check inicial para validar las hipótesis del modelo, establecer líneas base robustas y emplear herramientas de versionado como MLFlow o DVC para rastrear de manera efectiva modelos, datos y resultados.
El mantenimiento continuo de los modelos requiere una supervisión constante para detectar drifts (desviaciones en el comportamiento del modelo) y datos OOD (fuera de distribución), así como la recolección de métricas clave para evaluar su rendimiento. Además, es fundamental equilibrar adecuadamente los conjuntos de datos y mantener la consistencia en las divisiones para entrenamiento, validación y prueba, garantizando que el modelo sea fiable y escalable a largo plazo.