SQL
Bibliografía
- SQL for Data Analytics - Learn SQL in 4 Hours
- Escalabilidad vertical vs. horizontal: diferencias, ventajas, Kubernetes y cuál elegir
1. Introducción
SQL (Structured Query Language) es un lenguaje estándar de programación para gestionar y manipular bases de datos relacionales. Desarrollado en la década de 1970 por IBM, SQL permite realizar consultas, actualizar datos, eliminar registros, y crear y modificar estructuras de bases de datos. Su sintaxis es simple e intuitiva, facilitando su aprendizaje y uso.
2. Conceptos básicos
2.1. Introducción
A diferencia de herramientas como Excel, que están limitadas a gestionar un número limitado de filas, las bases de datos SQL son capaces de manejar grandes volúmenes de datos de manera eficiente.
Las bases de datos se clasifican en dos categorías principales:
- Relacionales: Almacenan datos estructurados en tablas organizadas en filas y columnas. Cada tabla tiene un identificador único que permite relacionarla con otras tablas.
- No relacionales o NoSQL: Almacenan datos no estructurados en formatos como grafos, documentos o pares clave-valor.
La siguiente tabla resume las ventajas y desventajas de cada tipo:
| Datos relacionales | Datos no relacionales | |
|---|---|---|
| Pros | Esquema estandarizado Gran comunidad de usuarios Lenguaje de consulta estandarizado ACID | Disponibilidad continua Velocidad de consulta Agilidad Costo |
| Contras | Dificultad de agrupación Normalización de datos Primero el esquema Escalado intensivo en recursos | No hay un lenguaje de consulta estandarizado Comunidad de usuarios más pequeña Se requieren habilidades de desarrollador Inconsistencia en la recuperación de datos |
2.1.1. Propiedades ACID en bases de datos relacionales
Las bases de datos relacionales destacan por garantizar la integridad y confiabilidad de los datos a través de las propiedades ACID, esenciales en entornos transaccionales como banca, comercio electrónico o cajas registradoras. Estas propiedades son:
- Atomicidad (Atomicity): Una transacción debe ejecutarse en su totalidad o no ejecutarse en absoluto. Si ocurre un fallo, todo se revierte.
- Consistencia (Consistency): Las transacciones llevan la base de datos de un estado válido a otro, cumpliendo con las reglas de integridad.
- Aislamiento (Isolation): Mientras una transacción está en curso, sus cambios no son visibles para otras transacciones hasta que se completa.
- Durabilidad (Durability): Una vez confirmada, la transacción persiste incluso ante fallos del sistema.
2.1.2. Escalabilidad en bases de datos
-
Bases de datos relacionales: Su escalabilidad es principalmente vertical, es decir, aumentar la capacidad de hardware de una sola máquina. Las bases NewSQL buscan combinar la robustez de los datos relacionales con la escalabilidad de sistemas NoSQL.

-
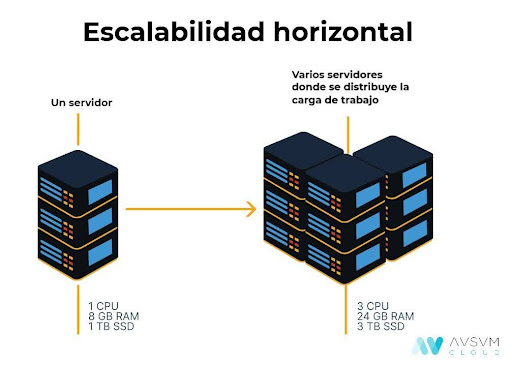
Bases de datos NoSQL: Destacan por su escalabilidad horizontal, mediante la distribución de datos en múltiples servidores, lo que reduce costos y mejora el rendimiento.
2.1.3. Interacción con bases de datos
Para interactuar con bases de datos relacionales, se utilizan consultas SQL o queries, agrupadas bajo las operaciones CRUD:
- Create (Crear)
- Read (Leer)
- Update (Actualizar)
- Delete (Eliminar)
2.1.4. Almacenamiento
Las bases de datos pueden almacenarse en:
- Servidores locales (On-Premise): Propiedad y mantenimiento a cargo de la empresa.
- Servidores en la nube (Serverless): Servicios administrados por terceros, como AWS o Azure.
2.1.5. Diagramas y estructuras
El ERD (Entity Relationship Diagram) es una herramienta visual para mapear las relaciones entre tablas dentro de una base de datos.
Las tablas se clasifican en dos tipos principales:
- Tablas de hechos (Fact tables): Almacenan datos principales para análisis, como registros de ventas o eventos.
- Tablas de dimensiones (Dimension tables): Proporcionan contexto adicional sobre los datos en las tablas de hechos, describiendo atributos como ubicaciones, segmentos de mercado o perfiles de clientes.
2.2. Palabras clave y estructura de las consultas SQL
Las consultas en SQL utilizan un conjunto de palabras clave que permiten seleccionar, filtrar, ordenar y limitar los datos en una base de datos. A continuación, se detallan las palabras clave más importantes, acompañadas de ejemplos prácticos para ilustrar su uso:
-
SELECT: Especifica las columnas que se desean recuperar de la base de datos.
EjemploPara seleccionar columnas específicas:
SELECT
job_title_short,
job_location
FROM
job_posting_factPara recuperar todas las columnas, utiliza
*:SELECT *
FROM
job_posting_fact -
FROM: Indica la tabla de donde se extraen los datos.
EjemploSELECT
job_title_short,
job_location
FROM
job_posting_fact -
WHERE: Permite filtrar las filas según una condición específica.
EjemploSELECT
job_title_short,
job_location,
job_via,
salary_year_avg
FROM
job_posting_fact
WHERE
job_title_short = 'Machine Learning Engineer' -
ORDER BY: Ordena las filas recuperadas. De manera predeterminada, el orden es ascendente; para orden descendente, se utiliza
DESC.EjemploSELECT
job_title_short,
job_location,
job_via,
salary_year_avg
FROM
job_posting_fact
ORDER BY
salary_year_avg DESC -
LIMIT: Restringe el número de filas devueltas por la consulta.
EjemploSELECT
job_title_short,
job_location
FROM
job_posting_fact
LIMIT 5 -
SELECT DISTINCT: Recupera solo filas únicas, eliminando duplicados.
EjemploSELECT DISTINCT
salary_year_avg
FROM
job_posting_fact
El orden correcto para estructurar una consulta SQL es el siguiente:
SELECTFROMWHEREGROUP BYHAVINGORDER BYLIMIT
Las palabras clave no son sensibles a mayúsculas o minúsculas, aunque se suelen escribir
en mayúsculas por convención. Se pueden añadir comentarios a las consultas SQL usando
-- para comentarios de una línea y /* */ para comentarios de varias líneas.
-- Este es un comentario de una línea
/*
Este es un comentario
de varias líneas
*/
2.3. Operadores y comparadores en SQL
En SQL, los operadores y comparadores se utilizan para realizar operaciones lógicas y comparaciones entre valores. A continuación se presentan algunos de los más comunes:
-
AND: Combina condiciones en una cláusulaWHERE. Todas las condiciones separadas porANDdeben ser verdaderas para que la fila sea incluida en el resultado.EjemploWHERE
condition1 AND condition2 -
OR: Combina condiciones en una cláusulaWHERE. Al menos una de las condiciones separadas porORdebe ser verdadera para que la fila sea incluida en el resultado.EjemploWHERE
condition1 OR condition2 -
NOTo<>: Niega una condición en una cláusulaWHERE. Si la condición después deNOTes falsa, la fila es incluida en el resultado.EjemploWHERE
NOT condition -
BETWEEN: Selecciona valores dentro de un rango.EjemploWHERE
column BETWEEN value1 AND value2 -
LIKE: Busca un patrón específico en una columna usando caracteres comodín.%representa cero, uno o varios caracteres.EjemploWHERE
column LIKE 'pattern%' -
IN: Comprueba si un valor está en una lista de valores especificados.EjemploWHERE
column IN (value1, value2, value3) -
>,<: Compara si un valor es mayor o menor que el especificado.EjemploWHERE
column > value -
>=,<=: Compara si un valor es mayor o igual, o menor o igual al especificado.EjemploWHERE
column >= value
Por ejemplo, si se desea seleccionar los trabajos de 'Data Scientist' o 'Machine Learning
Engineer' con un salario promedio anual entre 50000 y 100000, podríamos combinar los
operadores AND, OR y BETWEEN para formar una condición compleja en la cláusula
WHERE, obteniendo la siguiente consulta:
SELECT
job_title_short,
job_location,
job_via,
salary_year_avg
FROM
job_posting_fact
WHERE
(job_title_short = 'Data Scientist' OR job_title_short = 'Machine Learning Engineer') AND
salary_year_avg BETWEEN 50000 AND 100000;
2.4. Comodines (Wildcards) en SQL
Los comodines son caracteres especiales que se utilizan en SQL para buscar patrones en
cadenas de texto. Se utilizan en combinación con el operador LIKE en una cláusula
WHERE. Los comodines más comunes en SQL son:
-
%: Este comodín representa cero, uno o varios caracteres.EjemploPor ejemplo, si se desea buscar todos los trabajos que contengan la palabra 'Analyst' en cualquier parte del título, se podría utilizar la siguiente consulta:
WHERE
job_title LIKE '%Analyst%' -
_: Este comodín representa exactamente un carácter.EjemploPor ejemplo, si se desea buscar todos los trabajos cuyo título tenga exactamente 10 caracteres, se podría utilizar la siguiente consulta:
WHERE
job_title LIKE '__________'En este caso, cada guión bajo
_representa un carácter, y como hay 10 guiones bajos, se buscarán los títulos de trabajo que tengan exactamente 10 caracteres.
Es importante tener en cuenta que el uso de comodines puede hacer que las consultas sean
más lentas, especialmente si se utiliza el comodín % al principio de un patrón, ya que
en ese caso SQL tiene que buscar el patrón en todas las posiciones de cada valor de la
columna. Por lo tanto, se recomienda utilizar los comodines con cuidado y solo cuando
sean necesarios.
2.5. Alias
Los alias asignan nombres temporales a columnas o tablas, facilitando la lectura de consultas.
SELECT
job_title_short AS job_title
FROM
job_posting_fact
2.6. Operaciones
SQL permite realizar operaciones aritméticas como suma, resta, multiplicación, división y módulo.
SELECT
hours_spent,
hours_rate + 5 AS rate_hike
FROM
job_posting_fact
WHERE
rate_hike * hours_spent > 1000
En este caso, se está calculando un nuevo salario por hora (rate_hike) al sumar 5 al
salario por hora actual (hours_rate). Luego, se filtran los resultados para mostrar
sólo aquellos donde el producto de rate_hike y hours_spent sea mayor a 1000.
2.7. Agregación en SQL
Las funciones de agregación calculan un resultado único a partir de un conjunto de valores. Algunas funciones comunes son:
SUM(): Suma todos los valores en una columna.COUNT(): Cuenta el número de filas que coinciden con un criterio.AVG(): Calcula el promedio de una columna.MAX(): Encuentra el valor máximo en un conjunto.MIN(): Encuentra el valor mínimo en un conjunto.
Estas funciones se pueden usar con las cláusulas GROUP BY y HAVING:
GROUP BY: Agrupa filas que comparten una propiedad para aplicar funciones de agregación.HAVING: Filtra grupos basados en el resultado de una función agregada.
SELECT
-- Realizar la suma de todos los salarios
SUM(job_posting_fact.salary_year_avg) AS salary_sum,
-- Contar el número de filas que hay en la base de datos
COUNT(*) AS count_rows,
-- Contar el número de trabajos diferentes
COUNT(DISTINCT job_posting_fact.job_title_short) AS tipo_trabajos,
-- Promedio del salario
AVG(job_posting_fact.salary_year_avg) AS salario_promedio
FROM
job_posting_fact
WHERE
-- Ahora podemos aplicar todos los filtros anteriores pero
-- solo en aquellos casos donde el título del trabajo contenga el
-- término Machine Learning
job_posting_fact.job_title LIKE '%Machine%Learning%'
Otro ejemplo que muestra cómo se pueden usar estas funciones y cláusulas para obtener información más detallada sobre los trabajos:
SELECT
-- Nos quedamos con los tipos de trabajos
job_posting_fact.job_title_short as Trabajos,
-- Obtenemos el salario mínimo para cada puesto
MIN(job_posting_fact.salary_year_avg) as MIN_SAL_YER,
-- Obtenemos el salario máximo para cada puesto
MAX(job_posting_fact.salary_year_avg) as MAX_SAL_YER,
-- Obtenemos el salario promedio para cada puesto
AVG(job_posting_fact.salary_year_avg) as AVG_SAL_YER,
-- Contamos las veces que aparece un puesto de trabajo
COUNT(job_posting_fact.job_title_short) as JOB_COUNT
FROM
job_posting_fact
GROUP BY
-- Agrupamos los datos por el tipo de trabajo
Trabajos
HAVING
-- Filtramos aquellos trabajos que no se repitan más de 100 veces
-- Es muy útil para en el caso de calcular media no haya grandes
-- desviaciones
JOB_COUNT > 100
ORDER BY
-- Ordenamos las filas según el salario promedio anual
AVG_SAL_YER
2.8. Valores NULL en SQL
Los valores NULL en SQL representan la ausencia de información. Podemos filtrar estos
valores utilizando la cláusula IS NOT NULL en una consulta WHERE.
WHERE
salary_year_avg IS NOT NULL
Otra estrategia es reemplazar los valores NULL con un valor calculado, como el promedio
de los valores no nulos que pertenecen a la misma categoría. Por ejemplo, si tenemos una
tabla de ofertas de trabajo donde algunos registros tienen salarios publicados y otros
no, podríamos rellenar los valores NULL con la media de los salarios de la misma
categoría de trabajo.
UPDATE empleados
SET salario = (
SELECT AVG(salario)
FROM empleados AS e2
WHERE e2.trabajo = empleados.trabajo
AND e2.salario IS NOT NULL
)
WHERE salario IS NULL;
Este código actualizará la columna salario de la tabla empleados, estableciendo los
valores NULL al promedio de salario para cada tipo de trabajo. La subconsulta calcula
el promedio de salario para cada tipo de trabajo, excluyendo los valores NULL. Ten en
cuenta que este comando actualizará la tabla empleados en su lugar. Si no queremos
modificar la tabla original, podrías crear una nueva tabla o vista con los valores NULL
reemplazados.
2.9. Joins en SQL
Existen cuatro tipos de JOIN:
LEFT JOIN: Devuelve todos los datos de la tabla izquierda y las coincidencias de la tabla derecha.RIGHT JOIN: Devuelve todos los datos de la tabla derecha y las coincidencias de la tabla izquierda.INNER JOIN: Devuelve solo los datos que coinciden en ambas tablas.FULL JOIN: Devuelve todos los datos de ambas tablas, coincidan o no.
Si dos tablas contienen un identificador común y queremos combinarlas para obtener los datos asociados a ese identificador, como el nombre de la empresa, podemos hacer lo siguiente:
SELECT
job_postings_fact.job_id,
company_dim.name as Empresa
FROM
job_postings_fact
LEFT JOIN company_dim ON job_postings_fact.company_id = company_dim.company_id
En este caso, estamos utilizando un LEFT JOIN para combinar las tablas
job_postings_fact y company_dim basándonos en la columna company_id que es común en
ambas tablas. Como resultado, obtendremos una tabla que incluye el job_id y el nombre
de la empresa (Empresa) para cada registro en job_postings_fact. Si un job_id en
job_postings_fact no tiene una coincidencia en company_dim, el valor de Empresa
será NULL para ese registro.
3. Conceptos avanzados
3.1. Instalación de PostgreSQL en Linux
Para instalar PostgreSQL en Linux (PopOS en este caso), sigue estos pasos:
-
Instalación de PostgreSQL: Puedes instalar PostgreSQL desde el repositorio oficial de PostgreSQL o desde los repositorios de tu distribución. En PopOS, que está basado en Ubuntu, puedes usar
apt. Abre un terminal y ejecuta los siguientes comandos:sudo apt update
sudo apt install postgresql postgresql-contribEsto instalará PostgreSQL y algunas utilidades adicionales.
-
Interfaz de usuario gráfica (GUI): Aunque PostgreSQL no viene con una interfaz gráfica por defecto, puedes instalar pgAdmin, que es una interfaz gráfica popular para PostgreSQL. Puedes instalar pgAdmin desde el repositorio oficial o descargándolo desde su sitio web.
Alternativamente, puedes usar herramientas de línea de comandos como
psql, o integrar PostgreSQL con editores de texto como VS Code a través de extensiones. -
Configuración del firewall: PostgreSQL utiliza el puerto 5432 por defecto. Para permitir el tráfico a este puerto, asegúrate de que UFW (Uncomplicated Firewall) esté configurado correctamente:
sudo ufw allow 5432/tcp
sudo ufw status verboseVerifica que el puerto esté habilitado y que el firewall esté funcionando como esperas.
-
Creación de un usuario y una base de datos: Una vez instalado PostgreSQL, puedes crear un usuario y una base de datos. Primero, cambia al usuario
postgresy accede a la consolapsql:sudo -i -u postgres
psqlEn la consola
psql, ejecuta los siguientes comandos para crear un usuario y una base de datos:CREATE USER nombre_usuario WITH ENCRYPTED PASSWORD 'clave';
CREATE DATABASE nombre_database OWNER nombre_usuario;Reemplaza
nombre_usuarioynombre_databasecon los nombres deseados, yclavecon la contraseña deseada. -
Instalación de extensiones en VS Code: Para trabajar con PostgreSQL en VS Code, instala las siguientes extensiones:
- SQLTools: Proporciona soporte para consultas SQL y gestión de bases de datos.
- SQLTools PostgreSQL: Un complemento específico para PostgreSQL.
Puedes buscar e instalar estas extensiones desde la pestaña de extensiones en VS Code.
-
Permisos del usuario: El usuario creado no tiene permisos para crear bases de datos por defecto. Para otorgar permisos, ejecuta el siguiente comando en
psql:ALTER USER nombre_usuario CREATEDB;Esto permite que el usuario creado pueda crear nuevas bases de datos.
Además, algunos comandos útiles en psql son:
-
Listar bases de datos:
\l -
Listar usuarios:
\du
Estos comandos te permiten ver las bases de datos y los usuarios disponibles en tu instancia de PostgreSQL. Utiliza estos comandos para verificar el estado y la configuración de tu base de datos y usuarios.
3.2. Tipos de datos en SQL
En SQL, se emplean diversos tipos de datos para definir las columnas en una base de datos, asegurando la integridad y eficiencia en el procesamiento de consultas. Los tipos de datos más comunes son:
-
INT: Este tipo de datos se utiliza para almacenar números enteros.EjemploSi tenemos una tabla de
empleadosy queremos almacenar laedadde cada empleado, puedes usar el tipo de datosINT.CREATE TABLE empleados (
id INT,
nombre VARCHAR(100),
edad INT
); -
VARCHARoTEXT: Estos tipos de datos se utilizan para almacenar cadenas de caracteres.VARCHARrequiere que especifiques una longitud máxima para los caracteres.TEXTse utiliza para cadenas de caracteres de longitud variable.EjemploPodemos usar
VARCHARpara almacenar elnombrede los empleados.CREATE TABLE empleados (
id INT,
nombre VARCHAR(100),
edad INT
); -
BOOLEAN: Este tipo de datos se utiliza para almacenar valores booleanos, es decir, verdadero o falso (1 o 0).EjemploSi queremos almacenar si un empleado ha completado una tarea, puedes usar el tipo de datos
BOOLEAN.CREATE TABLE tareas (
id INT,
descripcion VARCHAR(255),
completada BOOLEAN
); -
TIMESTAMP: Este tipo de datos se utiliza para almacenar fechas y horas.EjemploPodemos usar
TIMESTAMPpara almacenar lafecha_de_contratacionde un empleado.CREATE TABLE empleados (
id INT,
nombre VARCHAR(100),
fecha_de_contratacion TIMESTAMP
); -
NUMERIC: Este tipo de datos se utiliza para almacenar números decimales o de precisión exacta.EjemploPodemos usar
NUMERICpara almacenar elsalariode un empleado.CREATE TABLE empleados (
id INT,
nombre VARCHAR(100),
salario NUMERIC(10, 2)
);En el ejemplo anterior,
NUMERIC(10, 2)significa que el salario puede tener hasta 10 dígitos en total, de los cuales 2 son decimales.
3.3. Manipulación de tablas en SQL
Para manipular tablas en SQL, se utilizan las siguientes instrucciones:
-
CREATE TABLE: Crea nuevas tablas.EjemploCREATE TABLE job_applied(
job_id INT,
application_sent_date DATE,
custom_resume BOOLEAN,
resume_file_name VARCHAR(255),
cover_letter_sent BOOLEAN,
cover_letter_file_name VARCHAR(255),
status VARCHAR(50)
);En el código anterior,
job_appliedes el nombre de la tabla y los parámetros dentro de los paréntesis son los nombres de las columnas con sus respectivos tipos de datos. -
INSERT INTO: Añade datos a una tabla.EjemploINSERT INTO job_applied(
job_id,
application_sent_date,
custom_resume,
resume_file_name,
cover_letter_sent,
cover_letter_file_name,
status
)
VALUES (1,
'2024-02-01',
TRUE,
'CV_01.pdf',
true,
'cover_letter_01.pdf',
'submitted'),
(2,
'2024-03-01',
TRUE,
'CV_02.pdf',
true,
'cover_letter_02.pdf',
'submitted'); -
ALTER TABLE: Modifica la estructura de una tabla existente.EjemploPodemos añadir una nueva columna a una tabla existente de la siguiente manera:
ALTER TABLE empleados
ADD COLUMN email VARCHAR(255);Aquí se añade una nueva columna llamada
emaila la tablaempleados. El tipo de datos de la nueva columna esVARCHAR(255).También podemos eliminar una columna existente de una tabla utilizando la instrucción
ALTER TABLE.ALTER TABLE empleados
DROP COLUMN email;En este caso, se elimina la columna
emailde la tablaempleados. -
DROP TABLE: Elimina una tabla y sus datos.EjemploSi queremos eliminar la tabla
empleados, puedes hacerlo de la siguiente manera:DROP TABLE empleados;peligroTen en cuenta que esta operación eliminará la tabla y todos los datos que contiene, por lo que debes tener cuidado al utilizarla.
Es una buena práctica hacer una copia de seguridad de tus datos antes de realizar operaciones que puedan resultar en la pérdida de datos.
3.4. Actualización de datos en SQL
La instrucción UPDATE en SQL se utiliza para modificar los datos existentes en una
tabla. Esta instrucción resulta muy útil cuando se necesita cambiar los valores de
ciertas filas o columnas.
UPDATE nombre_tabla
SET columna1 = valor1, columna2 = valor2, ...
WHERE condicion;
nombre_tablaes el nombre de la tabla que se desea actualizar.SETes la cláusula que se utiliza para especificar las columnas a actualizar y los nuevos valores que se desean asignar a esas columnas. Se pueden actualizar una o varias columnas a la vez.WHEREes la cláusula que se utiliza para especificar las filas que se desean actualizar. Si se omite la cláusulaWHERE, todas las filas de la tabla se actualizarán, lo cual puede no ser lo deseado.
empleados y se desea aumentar el salario detodos los empleados que tienen un salario inferior a 30000 en un 10%, se podría hacer de la siguiente manera:
UPDATE empleados
SET salario = salario * 1.1
WHERE salario < 30000;
En este caso, la cláusula WHERE se utiliza para seleccionar solo las filas donde el
salario es inferior a 30000. Luego, la cláusula SET se utiliza para aumentar el salario
de esas filas en un 10%.
Es muy importante utilizar la cláusula WHERE cuando se utiliza la instrucción UPDATE,
para evitar cambios no deseados en los datos. Siempre es una buena práctica hacer una
copia de seguridad de los datos antes de realizar operaciones que pueden modificarlos.
3.5. Tratamiento de columnas
En SQL, se pueden realizar varias operaciones en las columnas de una tabla:
-
Renombrar columnas utilizando
RENAME COLUMN.EjemploALTER TABLE job_applied
RENAME COLUMN contact TO contact_name; -
Cambiar el tipo de una columna utilizando
TYPE.EjemploALTER TABLE job_applied
ALTER COLUMN contact_name TYPE TEXT; -
Eliminar una columnautilizando
DROP COLUMN.EjemploALTER TABLE job_applied
DROP COLUMN contact_name;
3.6. Carga de datos en una base de datos SQL
La instrucción COPY se usa para importar datos desde un archivo CSV a una tabla.
COPY nombre_tabla
FROM ruta_archivo_csv
DELIMITER ',' CSV HEADER;
Aquí, nombre_tabla es la tabla destino, ruta_archivo_csv es la ubicación del archivo,
y DELIMITER ',' CSV HEADER indica el delimitador y que la primera fila contiene los
nombres de las columnas.
3.7. Funciones para fechas
SQL ofrece varias funciones para operar con fechas y horas:
-
::DATE: Convierte un valor de fecha y hora a solo fecha.EjemploSELECT fecha_hora::DATE FROM nombre_tabla; -
AT TIME ZONE: Convierte una fecha y hora a una zona horaria específica.EjemploSELECT NOW() AT TIME ZONE 'UTC'; -
EXTRACT: Obtiene partes específicas de una fecha.EjemploEjemplo para filtrar fechas de enero:
WHERE EXTRACT(MONTH FROM fecha) = 1;En este caso,
EXTRACT(MONTH FROM fecha)devuelve el mes de la fecha, y la condición= 1selecciona solo las fechas que corresponden al mes de enero.
3.8. Expresiones CASE en SQL
Las expresiones CASE en SQL se utilizan para crear diferentes resultados basados en
diferentes condiciones. Son similares a las declaraciones if-then-else en otros
lenguajes de programación.
Si se desea clasificar los trabajos en función del salario, se podría utilizar la siguiente consulta:
SELECT job_title,
CASE
WHEN salary_year_avg > 100000 THEN 'High'
WHEN salary_year_avg > 50000 THEN 'Medium'
ELSE 'Low'
END AS salary_category
FROM job_posting_fact;
En este caso, la expresión CASE clasifica los trabajos en 'High', 'Medium' o 'Low' en
función del salario promedio anual.
3.9. Subconsultas y CTEs en SQL
Las subconsultas y los CTEs (Common Table Expressions) son técnicas avanzadas de SQL que permiten realizar consultas más complejas.
Si se desea obtener el salario promedio de los trabajos de 'Data Scientist', se podría utilizar una subconsulta de la siguiente manera:
SELECT AVG(salary_year_avg)
FROM (
SELECT salary_year_avg
FROM job_posting_fact
WHERE job_title = 'Data Scientist'
) AS subquery;
En este caso, la subconsulta selecciona los salarios de los trabajos de 'Data Scientist', y la consulta principal calcula el salario promedio.
Un CTE es similar a una subconsulta, pero se define antes de la consulta principal y se puede referenciar varias veces en la consulta.
WITH data_scientist_jobs AS (
SELECT *
FROM job_posting_fact
WHERE job_title = 'Data Scientist'
)
SELECT AVG(salary_year_avg)
FROM data_scientist_jobs;
En este caso, el CTE data_scientist_jobs selecciona los trabajos de 'Data Scientist', y
luego se utiliza en la consulta principal para calcular el salario promedio.
3.10. UNION en SQL
La operación UNION combina los resultados de varias consultas SELECT.
Ejemplo para obtener títulos de trabajo únicos de 'Data Scientist' y 'Machine Learning Engineer':
SELECT job_title
FROM job_posting_fact
WHERE job_title = 'Data Scientist'
UNION
SELECT job_title
FROM job_posting_fact
WHERE job_title = 'Machine Learning Engineer';